https://morgenrot.net/
さて前前回、Ubuntu 22.04 環境で Nerfstudioのセットアップを行いました。前回はConda仮想環境 を立ち上げて作業ができました。今回はどのようなデータセットを作って分析するのかを考えてみましょう。
前回記事:その2
https://techietechnology.co.jp/2025/03/10/nerfstudio-setup-sono2/
その前にハードウェア構成について考えをまとめておきます。Nerfstudioのハードウェア構成ですが、Gaussian SplattingはNeRF(Neural Radiance Fields)より高速に動作するといっても、高いスペックが有効です。
入力画像から高品質な3D表現を推定する先進的な技術であり、膨大な演算資源を必要とします。特に学習処理はGPUに依存するため、高性能なNVIDIA GPUを搭載したワークステーションが推奨されます。推奨というより必須です。
2025年時点で1台のワークステーションで導入を考えた場合は以下のような構成になります。
- GPU: RTX 4090/5090クラス、またはRTX 6000 Ada/A6000クラス
- CPU: 多コア・高クロック型ワークステーション向けプロセッサ
- メモリ: 大容量(ECC対応含む)
- OS: Ubuntu(LTS推奨)
- マザーボード:PCIeレーン数が豊富でGPUをフル帯域で接続しやすいもの
- 拡張性: マルチGPUなどスケールアップを考慮
- ワークステーション1台での運用
学習は主にGPUで実行されますが、前処理やデータロード、GPUへのワークロード配分などでCPUも重要です。大規模シーンの解析ではコア数とCPUクロックの両方が効き、さらにマルチGPU運用を視野に入れる場合はPCIeレーン数も重要になります。
もしGPUを1枚のみ搭載する程度であれば、Intel Core i9やAMD Ryzen 9クラスでもよいでしょう。より大きなプロジェクトを考えた場合は、AMD Ryzen Threadripper PROなどPCIeレーン数に余裕のあるワークステーション向けCPUの方が無難でしょう。Intel Core i9やAMD Ryzen 9クラスであれば、BTOショップで購入するのがよいでしょう。
もっとも重要なポイントは、GPUです。コンシューマクラスでは、NVIDIA GeForce RTX 4090 (24GB)や、RTX 5090(32GB )です。ワークステーションクラスではRTX A6000(48GB ) / RTX 6000 Ada(48GB )です。BTOショップでもワークステーションとして提供されることが多くなります。
さらにその上のデーターセンタークラスではNVIDIA A100 (40GB / 80GB)、NVIDIA H100 (80GB / 94GB)となります。このクラスはサーバーベンダーやSIer(システムインテグレーター)がソリューションとして提供しています。
NeRF StudioやGaussian Splattingもそうですが、AI関係をローカルで動かしたい場合は、複数GPUを使うことで大規模シーンの学習時間短縮や並行ジョブ実行が可能になります。まずはGPUをシングルで使う場合でも、マルチGPU対応のものをあらかじめ考えておくとよいでしょう。マルチGPUを視野に入れるとPCIeレーン数が必須です。最近ではIntel Xeonシリーズが微妙なのでAMD Ryzen Threadripper PROシリーズを選ぶしかありません。GPUはNVIDIA一択しかありません。
システムメモリに関しては、8チャネル構成であれば128GB~256GBあたりでECC対応メモリをサポートしているならECCもよいでしょう。ストレージに関してはなかなか難しく、高速なPCIe接続のNVMe SSDを複数枚RAIDなどでまとめるか。同じく高速なThunderbolt 4/USB4接続の外部ストレージをするか。ほかにも100GbE、8TBなど単体のNVMe SSD、2枚程度のRAIDなどさまざまな方法があります。多数の画像やシーンデータを一気に読み込み・書き出しするタスクでは、NVMe RAID超高速連続読み書きができると非常に快適です。
話がそれてしまいましたが、前回は Nerfstudio の公式サンプルデータセットをご紹介いたしました。実際に以下のコマンドを実行することで、テスト用のデータ一式が data/nerfstudio/poster ディレクトリ内に展開されます。
ns-download-data nerfstudio --capture-name=posterこのディレクトリには、Nerfstudio が扱うデータセットの典型的な構成例が一通り含まれており、学習や推論の際にどのようなファイルが必要になるかの参考になります。実際に data/nerfstudio/poster を確認してみると、以下のような構成になっていることがわかります。
base_cam.json
colmap
images
images_2
images_4
images_8
sparse_pc.ply
transforms.jsonまず base_cam.json ですが、これはカメラの初期設定や共通パラメータをひとまとめにした JSON ファイルです。複数のフレームや複数のカメラが存在する場合に、共通部分だけをこちらに定義して、差分はtransforms.json などで補うといった方法がとられることもあります。
images2_4_8はさまざまな解像度(1倍、1/2、1/4、1/8)の画像フォルダです。それぞれ異なる解像度で画像が格納されたディレクトリ群です。具体的には、オリジナルの1 倍解像度や 1/2、1/4、1/8 といったスケールの画像が用意され、Nerfstudio 側が用途や負荷状況に応じて使い分けたりします。
colmapは、複数枚の画像からカメラの外部パラメータおよび内部パラメータなどを推定し、同時にシーンの 3D点群を再構築できる強力なオープンソースソフトウェアです。COLMAP は学術研究や実務の場面で広く用いられていますが、その高い精度の代わりに処理時間がかなりかかる場合があるため、プロジェクトによっては別の 3D 再構築ソフトを利用することも珍しくありません。
sparse_pc.ply というファイルには、疎な点群がテキスト形式で格納されています。通常の PLY 形式ではヘッダ情報などが含まれますが、ここでは単純に各行に座標 (X,Y,Z) と色 (R,G,B) の簡易フォーマットを採用しており、推定された特徴点の座標および色情報のみが保持されています。疎点群であるため、シーン全体の詳細を完全に表すわけではなく、あくまでカメラ位置推定の副産物として得られた特徴点の集合であることが多いです。
transforms.jsonは、Nerfstudioでカメラの外部・内部パラメータを定義しているJSONファイルです。 画像のファイルパスと、それに対応するカメラ変換行列(transform_matrix) がまとめられており、焦点距離(fl_x, fl_y) や歪み係数(k1, k2, p1, p2) などのパラメータも含んでいます。このファイルを参照学習や推論を行います。
これらのファイルすべてを毎回必ず活用するわけではなく、一般的には任意の解像度の images_~ ディレクトリや sparse_pc.ply, transforms.json あたりが主に利用されるケースが多いと考えられます。
同様の仕組みは、PostShotでも見られます。PostShot では独自にカメラ位置を推定できる機能を備えていることがありますが、より洗練されたカメラパラメータ推定や 3D 再構築が必要な場合には、COLMAP のような別の高精度なソフトウェアを組み合わせることがしばしば行われます。
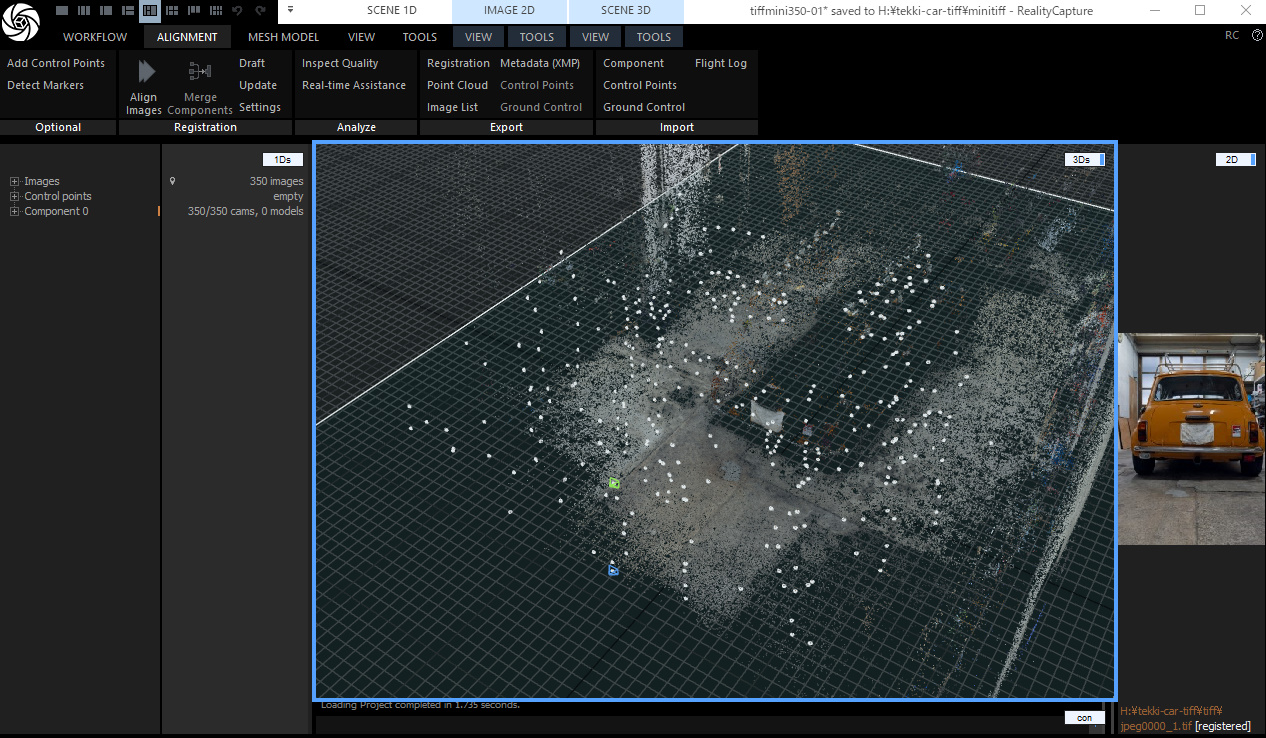
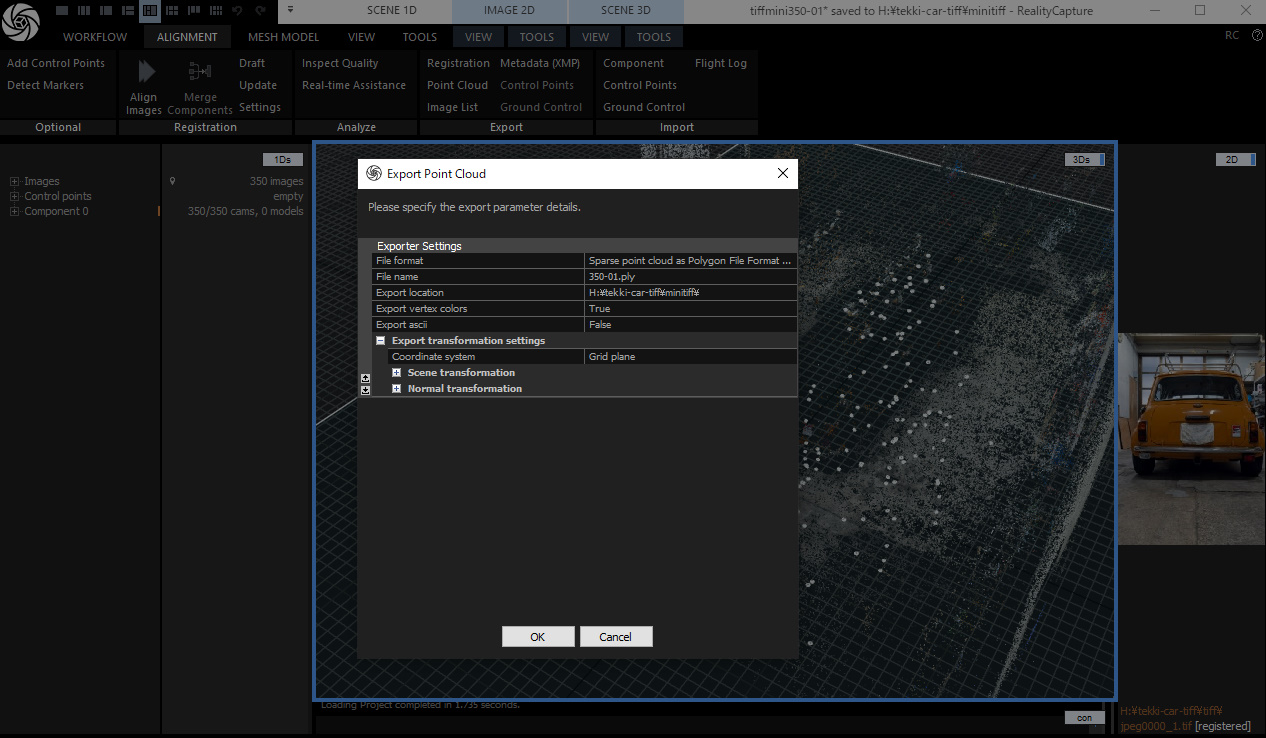
では、実際に RealityCapture を用いて 350 枚の画像をアライメント(Alignment)しました。各画像のカメラ姿勢(位置・回転)とレンズの内部パラメータが推定できました。また、特徴点を三角測量して得られる疎な 3D 点群(スパースクラウド)も同時に生成されています。
RealityCaptureの使い方は少し学ぶ必要があります。今回は省略してお伝えします。レジストレーションと点群でそれぞれのデータを書き出しできます。sparse_pc.plyとtransforms.jsonに相当するデータを作ります。

レジストレーションは、内部/外部カメラパラメータを選択します。英語表示の場合は英語です。

点群はSparse pointを選びます。Exprot asciiはYes(はい)にしましょう。これ重要です。Postshotの場合はNoです。

RealityCaptureからのデータは、 Nerfstudioで処理できるように形式を変換する必要があります。Nerfstudioのフォルダーに移動します。以下注意して確認してください。
ドキュメント
https://docs.nerf.studio/quickstart/custom_dataset.html#realitycapture
RealityCaptureのデータを変換するコマンド
ns-process-data realitycapture \
--data /home/画像フォルダ \
--csv /home/RealityCaptureのcsv \
--ply /home/RealityCaptureのply \
--output-dir /home/画像フォルダ出力先 \
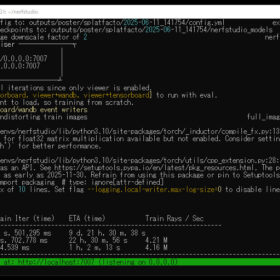
--max_dataset_size -1このようなコマンドを実行することで、RealityCapture が出力した CSV (カメラパラメータ) と PLY (点群) を、Nerfstudio がスムーズに参照できる形式へと変換できます。変換処理が問題なく完了すると、以下のようなメッセージが出力され、正しくコンバートされたことを示します。
🎉 Done copying images with prefix 'frame_'. process_data_utils.py:348
🎉 🎉 🎉 All DONE 🎉 🎉 🎉
Started with 350 images
Final dataset is 350 frames.以上でNerfstudioへデータを供給するための準備が整いました。Postshotと比較するとやや面倒に感じる部分も多いかもしれません。Ubuntu 上の環境構築や仮想環境の準備、そしてこの形式変換など、多少の手順を踏む必要はありますが、それによってさまざまなプリセットやマニュアル的なオペレーションを自由に試せる利点があるため、ある程度の手間を掛ける価値があるといえるでしょう。
この辺りの作業は実際に手を動かさないと理解しにくいです。時間を確保してubuntuとwindowsでデータをいったり来たりすることで上手くゆきます!
その4につづく
https://techietechnology.co.jp/2025/03/26/gaussiansplatting-vs-photogrammetry/